AT319 Lab #7 UAS Data Raster Analysis
- Leighton Moorlach

- Mar 6, 2022
- 5 min read
Updated: Apr 14, 2022
Overview:
In my previous lab I completed some ESRI tutorials regarding raster data analysis. This week I engaged in raster data analysis using UAS data gathered over the course of a mine dredging operation. For this lab, I had to draw upon what I learned in the ESRI tutorials.
I used the Litchfield dataset provided to us my Professor Hupy. In this lab I used the follow ArcGIS Pro tools:
Extract by Mask (A raster clip within Geospatial Analysis) (cookie cutter)
Resample
Fill
Deliverables
A map layout with correct cartography elements after each form of analysis
The Data
Here is a background on the data I used for this lab written by Dr. Hupy:
The dataset you are using is from a real world application/consulting project that I engaged in (and won an award from). The example here is a mine that did not trust the dredging operation as they thought they were getting overcharged. We will deal with volumetrics in a follow up lab, but here I want to get you to work with the UAS data and engage in some raster analysis. As stated before, you should now be familiar with many of these tools, so you will not be getting too much step by step. I am more so going to provide you with some real life scenarios and you will need to engage in the processing needed. (I will give you hints along the way.
We begin on the 4th of July to where the mine operation tells of the dredging to take place, and for us to establish a base dataset to know how much material was added. They are also concerned about slope failure and low lying flat areas where water will collect. Because the area flown is pretty large, we will want to clip out the area to work with. I have already drawn this polygon for you to standardize the operation. In a following lab on volumetrics, you will create your own clips. We will then want to resample our data to standardize the cell size.
· Begin by getting familiar with the data. Drag the following datasets into your project:
o dsm_20170704
o ortho_20170704
o dsm_20170722
o ortho_20170722
o dsm_20170827
o ortho_20170827
o Dredgepile_clip
Below I have listed the cell size, projection, highest elevation, and lowest elevation for each of the DSM rasters in the database.
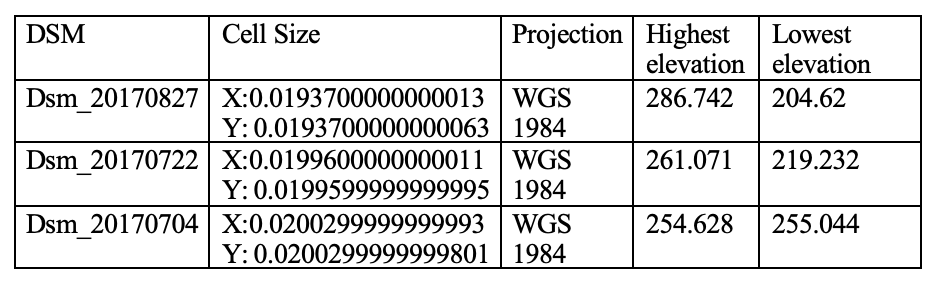
Table 1: The cell size, projection, highest elevation, and lowest elevation for each of the DSM rasters in the database.
Analysis
For the first part of the analysis I worked with just the dredge pile of the operation. I engaged in an extract by mask starting with the dsm_20170704 raster layer with the following settings:
Input raster: dsm_20170704
Input raster or feature mask data: Dredgepile_clip
Output raster: dsm_20170704_clipped
The new high elevation is: 244.559
The new low elevation is: 225.743
The appearance changed in the center of the map, it appeared to get lighter in the clipped area.
The cell size is pretty small. I don’t need a cell size this small to engage in what I was doing, so I needed to resample. There are different types of resampling, I have listed those below:
Nearest— Nearest neighbor is the fastest resampling method; it minimizes changes to pixel values since no new values are created. It is suitable for discrete data, such as land cover.
Bilinear— Bilinear interpolation calculates the value of each pixel by averaging (weighted for distance) the values of the surrounding four pixels. It is suitable for continuous data.
Cubic— Cubic convolution calculates the value of each pixel by fitting a smooth curve based on the surrounding 16 pixels. This produces the smoothest image but can create values outside of the range found in the source data. It is suitable for continuous data.
Majority—Majority resampling determines the value of each pixel based on the most popular value in a 3 by 3 window. Suitable for discrete data.
The best type is use in my case was bilinear and cubic because those can be used for vector data. I ran the resample tool with the following settings:
Input raster: dsm_2017_clipped
X and Y cell size 50cm
Resample technique: bilinear
Output name: dsm_20170704_clipped_50cm
I then performed a raster extract and resample for the following datasets:
Dsm_20170722
Dsm_20170827
After that, I generated a hillshade for each of those datasets. Before I did analysis, I wanted to clean up the ‘noise’ on the July 22 and the August 27 datasets. So, I engaged in a fill operation on those to get rid of the noise on the ground. I used the 'fill' tool with the following settings:
Input surface raster: dsm_20170722_clipped_50cm
Output surface raster: fill_20170722_25cm
Z limit: .25
I repeated the process with the August 27th dataset.
Engaging in Analysis
On August 27th, the mine owner was worried about the extent of flooding at the bottom of the dredge pile. Looking at the orthomosaic shows that they created a holding area for the water. Clearly that area should be flat. I used my fill_20170827_25cm to engage in an aspect analysis. Then used the map calculator to find all the flat areas.

Fig. 1: August 27th map of the flat areas of the dredge pile.
In working with the August 27 dataset, I noticed that water is collecting between 233 and 234 meters. I needed to see if the containment area had this criteria. I used the fill_20170827_25cm and map algebra to find all areas between 233 and 234 meters.

Fig. 2: August 27th map of the water collection areas between 233 and 234 meters.
By the time July 22 comes around, the dredge operation is well underway, and with that comes the risk of slope failure. If the material is wet, albeit not saturated, it tends to ‘stick’ and the slopes values are high. The issue is that as the material dries out, the slopes fail. Slope failure can occur on the pile when they exceed 30 degrees. I am mainly concerned about the south slopes that are above 30 degrees and want to get those smoothed out, or at least avoid them when conducting operations. I needed to find out if the pile is safe by locating all south slopes that exceed 30 degrees using the fill_20170722_25cm.

Fig. 3: July 22nd map of the south facing slopes that are greater than 30 degrees.
On August 27th the dredge pile has gotten pretty large. The mine is concerned about slopes on the upper reaches of the pile. They want to find out two things:
How much of the pile is more than 245 meters elevation using fill_20170827_25cm.
In that upper area, how much of the slope is more than 30 degrees using fill_20170827_25cm.

Fig. 4: August 27th map areas of the pile where the elevation is greater than 245 meters and the slope is greater than 30 degrees.
Although volumetric analysis has been going on this entire time, I wanted to get an idea of the changes that have occurred. I wanted to see how much of a difference there is on the pile between the August 27 date and July 22 and July 4. I generated the following new datasets using the non-filled resampled to 50cm data sets:
The difference between July 22 and July 4

Fig. 5: Map of the difference between the DSM models on July 22nd vs July 4th.
The difference between August 27 and July 4

Fig. 6: Map of the difference between the DSM models on August 27th vs July 4th.
The difference between August 27 and July 22

Fig. 7: Map of the difference between the DSM models on August 27th vs July 22nd.
The problem with this geoprocessing operation with the data that I used is that the model and data are constantly changing due to dredging operations and erosion of the mine. To effectively engage in this type of analysis it would be best to have a stagnant data set.



Comments